
CSAPP
计算机系统漫游
- 代码从文本到可执行文件的过程(c语言示例):
- 预处理阶段,处理 #inlcude <stadI/O.h>, #define MAX 100
- 编译阶段:将文本编译成汇编程序,hello.s
- 汇编阶段:汇编器将上一步的程序翻译成机器指令。hello.o
- 链接阶段就:hello 中调用的printf函数,而函数存在一个printf.o 单独的编译完成文件,需要以某种方式合并到hello.o 中。
- 系统的硬件组成
- 总线
- I/O设备
- 主存
- 处理器, 指令集合: 加载(复制内容到寄存器), 存储(从寄存器到存储),操作(加减乘除等计算), 跳转(覆盖程序计数器PC的数值,执行代码跳转)
- 缓存, 高速缓存
- 操作系统如何管理硬件
- 任何的硬件通过操作系统提供服务, 所有应用程序都是建立在操作系统之上的。
- OS 的基本功能: 1. 防止硬件被滥用, 2. 提供一套简单一致的机制来控制复杂度而又大相径庭的低级硬件设备。
- OS 的抽象: 文件 -> I/O, 虚拟存储器 -> 主存+磁盘, 进程 -> 处理器,主存,I/O设备的抽象
- 抽象
- 进程: 计算机科学中最重要并且成功的概念。
提供一种假象, 好像系统上只有这个程序在运行,看上去只有这个程序在使用处理器、主存、和I/O设备. 这是通过处理器在进程间切换来实现的。 操作系统实现这种交错执行的机制为 上下文切换, 实现进程这个抽象概念需要低级硬件和操作系统软件之间的紧密合作。
- 进程: 计算机科学中最重要并且成功的概念。
- 线程:每个线程都运行在进程的上下文中,并共享同样的代码和全局数据,服务器对于并行处理的需求,导致线程编程成为越来越重要的编程模型, 一般来说,多线程之间更容易共享数据,也比进程更轻量。
- 虚拟存储器: 为进程提供了一个抽象、一致的存储空间,称为虚拟地址空间。包括: 程序代码和数据,堆,共享库,栈,内核虚拟存储器。
- 文件: 字节序列。包括磁盘,键盘,显示器,网络,都可以视为文件。
- 并行跟并发的区分: 并发: 好像 同时具有多个活动在系统中。 并行:真正的并行。
- 抽象: 抽象的使用是计算机科学中最为重要的概念之一,因为,程序员无需了解它内部的工作变可以使用这些代码。在处理器中,指令集结构提供了对实际处理器硬件的抽象。机器代码程序表现的好像是运行在一个一次执行一条指令的处理器上。底层的硬件币抽象描述的要复杂精细的多,它并行的执行多条指令,但又总是与那个简单有序的模型保持一致。
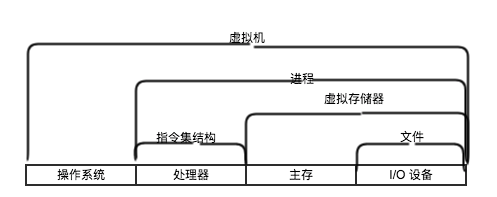
计算机系统中一个重大的主题就是 提供不同层次的抽象表示,来 隐藏实际实现的复杂性
信息的表示和处理
因为只是介绍了二进制、无符号数、有符号数、以及小数的表示方法, 计算机教程中都有介绍,所以省略不写了。只是简单的摘录重要的。
- 在相同长度的无符号和有符号整数之间 进行强制类型转换时候,大多数C语言实现遵循 原则是 底层的位模式不变。而是改变位的解释方法。
- 编码的存储长度有限。可能导致数值溢出。需要非常注意。
- 整数和浮点数的表示方法,有所区别,导致, 整数可以进行移位、结合等优化方法,但是浮点数则不行,如 x * y * z 不等于 y * z * x 需要注意
程序的机器级别表示
精通细节是理解更深和更基本概念的先决条件, 所以魔鬼隐藏在细节之中。*
- 机器代码的产生过程
机器代码, 用字节序列编码低级的操作,包括处理数据、管理存储器、读写存储设备上的数据、以及利用网络通信。 编译器机基于编程语言的原则、目标机器的指令和操作系统遵循的原则, 经过一系列的阶段产生机器代码。GCC C语言编译器以汇编代码的形式产生输出,然后调用 汇编器和链接器从而根据汇编代码生成可执行的机器代码。
- 抽象:
- 指令集体系结构(ISA): 屏蔽了处理器的硬件实现,将指令的执行描述为,简单的顺序执行(处理器的硬件远远比描述的精细复杂)
- 存储抽象: 抽象成一个大的字节数组,存储器的实现是,将多层硬件存储器和操作系统软件的结合
- 主要内容:
- 了解C语言中的控制结构, 比如if while switch 语句的实现方法。
- 过程的实现, 包括程序如何维护一个运行栈来支持过程间数据和控制的传递以及局部变量的存储
- 数组、结构、联合这样的数据结构的实现方法
- 指令集:
- 指令操作数
- 源数据: 常数、寄存器、存储器
- 类型: 立即数(常数)、寄存器、存储器
- C 语言的指针就是地址,间接引用指针就是将该指针放在一个寄存器中,然后在存储器引用中,使用这个寄存器, 局部变量通常保存在寄存器中。
- 数据传送指令: mov
- 算数逻辑操作: add, sub, imul, sal, shl, leal, imull, mull, idivl, divl
- 控制:条件码,跳转指令,test, sete, sets, setg etc, cmp, jmp, 条件码一般使用比较、算数、直接设定三种方式, 跳转指令则利用,条件码来进行跳转或者间接跳转
- 栈: push, pop
- C 语言 控制结构 汇编表示
-
while, for 一般是先将 for 循环转变为等价的 while 循环,while 循环 套用固定的汇编代码 模式。
do body-statement while(test-expr) loop: body-statement t = test-expr; if(t) goto loop; done: while(test-expr) body-statement t = test-expr; if(!t) goto done; loop: body-statement t = test-expr; if(t) goto loop; done: -
switch 的实现
使用跳转表 实现,来达到 执行时间跟 开关数量无关。 -
条件传送指令
因为现代处理器的流水线设计,导致在条件判断时候,才能确定下一条执行指令的位置,而导致按照顺序执行 准备的代码可能被抛弃,而对应的准备工作则变为了浪费。 而 条件传送 指令先计算出条件操作的两种结果,然后根据条件来选择满足的结果。从而避免了 因为跳转指令 带来的资源浪费。另一方面现代处理器都采用了 分支预测 逻辑,来试图猜测每条跳转指令是否被执行。(处理器设计试图达到 90%的正确率),正确的预测可以没有代价,然而额错误的预测则会带来严重恩惩罚,大约 20-40 的时钟周期的浪费,导致性能严重下降。
举例: 例如简单 三目运算符, x > y ? x+y : x-y, 当两个表达式具有副作用的时候则不能应用。
-
- 结构实现:
- 数组分配和访问: 基本实现为, 在存储器中分配一个连续的 T A[N], L * N 字节的连续大小的空间。 L为T类型的字节大小。而C语言中数字指针的实现(ptr ++ )则实现为单纯的 地址运算。嵌套数组 则以 行优先、列优先 的方式进行展开。
- Struct 的实现, 变量为 首地址 + 偏移量。
- 数据对齐: 计算机系统对 基本数据结构类型的大小做了限制,8的倍数等。这种 对齐限制,简化了 处理器和存储系统之间的硬件设计。
- 过程实现
过程调用 包括数据传递(过程参数、返回值)、控制跳转。在进入是为过程的局部变量分配空间,并在退出时候释放这些空间。-
简单指令:
转移控制: call, leave, ret.
call: 将返回地址入栈(call之后的下一条命令的地址) 2. 跳转到被调用的过程处。
ret: 从栈中弹出地址,并跳转到此位置。需要将栈指针指向call指令存储的放回地址的位置(需要自己控制)
leave: movl %ebp, %esp; popl %ebp 为ret 返回做好准备工作如果使用整数,指针作为返回值的话,可以使用%eax传递。(其他的呢?)
寄存器使用: 寄存器是计算中公用的资源。为了保证 被调用者不会覆盖调用者时候用的寄存器的数值。需要遵守规范。
%eax, %edx, %ecx 调用者保存寄存器, %ebx, %esi, %edi 被调用者保存寄存器。 需要调用者与被调用者配合来保护共享的寄存器内容。 -
实现过程:
函数调用过程的两个寄存器 %ebp(帧指针), %esp(栈指针) 帧指针保存当前过程的最高位置,%esp则向下增长, 用于分配必要的地址空间,调用函数参数等。 在调用时, 首先压入调用参数,返回地址, 压入%ebp, 调用后,将 %ebp 重置为当前的%esp, 标记确定当前的 函数的最高地址。返回时, movl %ebp, %esp; popl %ebp; ret; 恢复调用函数之前的样子。天生的具有递归属性。
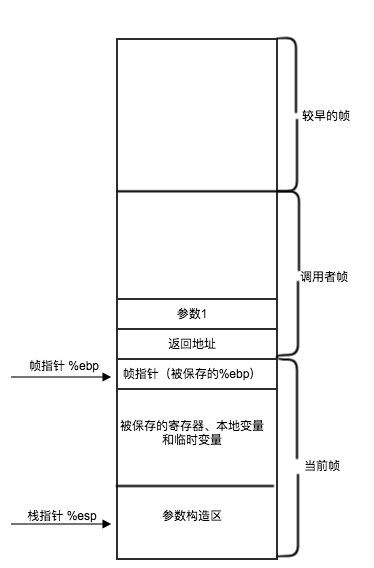
- 什么时候需要帧指针:
- 局部变量太多,不能都存在在寄存器中
- 有些局部变量是数组或者结构
- 函数用取地址操作符&,来计算一个局部变量的地址
- 函数必须将栈上的某些参数传递到另一个函数
- 在修改一个被调用者保存寄存器之前,需要保存它的状态
- X86-64 中对于过程的 一些具体优化:
- 参数通过寄存器传递到过程,而不是在栈上,消除了在栈上存储和检索值的开销
- call 指令将一个64位的返回地址存储在栈上
- 许多函数不需要栈帧,只有那些不能将所有局部变量存储在寄存器中的函数才需要在栈上分配空间
- 没有帧指针,作为替代,对栈位置的引用相对于栈指针。
-
- C 语言 指针
- 每个指针都对应一个具体的类型: 指针类型不是机器代码中的一部分,C语言提供的一种抽象,地址运算,来避免寻址错误。
- 每个指针都有一个值, 这个值是某个指定类型对象的地址。
- 指针用& 运算符创建
- 运算符 * 用于指针的 间接引用
- 数组与指针紧密关联
- 指针类型转换: 只改变类型,而不是值
- 指针可以指向函数,指向 函数机器代码中的 第一条 指令地址
C语言跟汇编指令 的差别很大,在汇编语言中,各种数据类型之间的差距很小,程序以指令序列来表示。每条指令是一个单独的操作。编译器必须提供多条指令来产生和操作各种数据结构,来实现像条件、循环、和过程这样的控制结构、抽象机制。
处理器体系结构
一个处理器支持的指令和指令的字节编码称为它的 指令集体系结构 (ISA)ISA的编译器编写者和处理器设计人员之间提供了一个概念抽象层。现代处理器的实际工作方式可能跟ISA 隐含的计算模型大相径庭 –>
- 目的
- 设计 Y86 处理器,首先是基于顺序的、功能正确的处理器设计
- 创建一个流水线化的处理。处理器可以同时执行五条指令的不同阶段
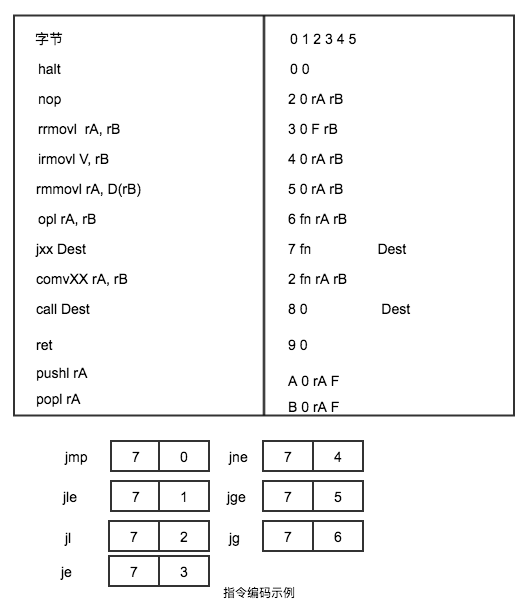
- Y86 指令编码,
-
具体的描述了, 指令的机器字节表示。字节编码必须有唯一 的解释,任何一个字节序列要么是一个唯一的指令序列的编码,要么就不是一个合法的字节序列。 每条指令的第一个字节码都有唯一的代码和功能组合。给定这个字节,我们就可以决定所有的其他的附加字节的长度和含义。这个性质确保处理器可以无二义性的执行目标代码程序。反汇编程序的翻译解释,就是如此。
RISC(精简指令集) 和 CISC(复杂指令集):简单的指令集形式可以产生更搞笑的代码, 实际上,许多加到指令集中的高级指令很难被编译器产生,所以也很少被利用。90年代,沉沦逐渐平息,无论是淡出的RISC,还是单纯的CISC都不如结合两者思想精华的设计。今天的RISC机器的指令表,已经有数百条指令,几乎与 精简指令集机器 的名字不相符了。那种将实现细节暴露给机器级程序的思想已经被证明是目光短浅的。(RISC做过这样的事情?)
-
- Y86 的实现:
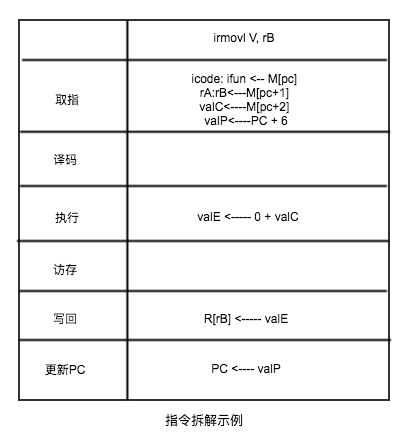
- 拆分指令为阶段:
- 取指: 取指阶段从存储器读取指令字节,地址为程序计数器的值,从指令中 抽取出 指令的,icode, ifun, 操作的字符, rA, rB, 常数
- 译码: 译码阶段从寄存器文件读入最多两个操作数,得到值, valA, valB等。
- 执行: ALU运算,
- 访存: 可以将数据写入存储器,或者从存储器读出数据。
- 写回: 将结果写回到寄存器文件
- 更新PC: 将PC设置成为下一条指令的地址
在设计硬件时候, 一个非常简单而一致的结构是非常重要的。降低复杂度的一种方法是,让不同的指令共享尽量多的硬件,因为在硬件上复制逻辑快比用软件来处理困难的多。
- 硬件结构 (SEQ)
- 组合电路从本质上讲,不存储任何信息,他们只是简单的响应输入信号。 产生等于输入的某个函数的输出。
- 时钟寄存器: 存储单个位,或字,时钟信号控制寄存器加载输入值
- 随进访问寄存器: 存储多个字,用地址来选择该读或者写。应用有:寄存器文件, %eax etc
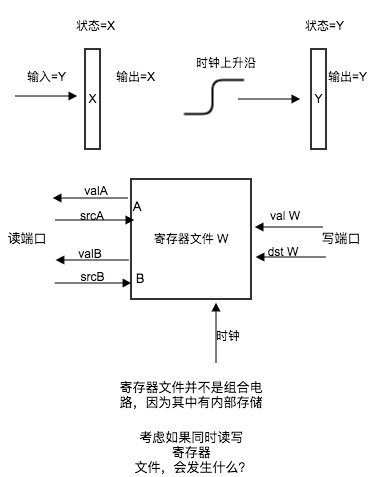
- 流水线通用原理:
流水线化的一个重要特性就是增加了系统的吞吐量(单位时间内服务的顾客的总数),代价是可能稍微的增加了延迟(服务一个用户所需的时间)。举例来说, 一个客户需要沙拉,在一个非流水线化的服务中,非常简单,只需要在沙拉阶段停留。但是在一个流水线化的服务中,则需要无谓的其他阶段的等待。
- 流水线的局限性: 运行时钟的速率是由最慢的阶段的延迟限制的。所以对于硬件设计者来说,将系统计算设计成 具有相同延迟的阶段 是一个严峻的挑战。
- 预测下一个PC:
- 流水线的设计目的是 每个时钟周期 都发射一条指令,也就说每个时钟周期都有一条新的指令进入执行阶段并最终完成。
- 要做到这一点就 需要在取出当前指令之后,马上确认下一条指令。
- 如果取出的指令是条件分支指令,要到几个周期之后,才能确定是否要选择分支。(jxx)类似的是ret
- 分支预测和处理预测错误
- 流水线冒险: 将流水线引入一个带反馈的系统,当相邻指令间存在相关时会导致出现问题, 这些相关可能会导致流水线产生计算错误,称为冒险。
- 数据相关: 下一条指令会用到这一条指令计算出的结果。(数据冒险)
- 控制相关: 一条指令要确定下一条指令的位置。例如执行条件跳转。(控制冒险)
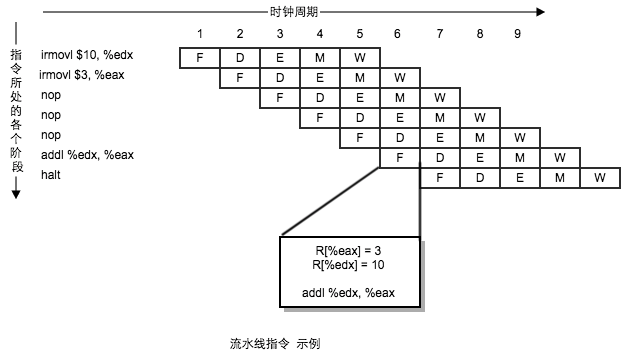
- 控制逻辑:
- 处理ret
- 加载使用冒险
- 预测错误的分支: 在分支逻辑发现不应该选择分支之前,分支目标处的几条指令已经进入到了流水线中,必须从流水线中舍弃这些操作
- 当一条指令发生异常,需要禁止后面的指令更新 程序员可见状态,并且在异常指令到达写回阶段时,停止执行。
- 通用的冒险简单解决办法:
- 暂停来避免冒险: 让一条指令停留在译码阶段,直到他需要的操作数的指令通过了写回阶段,这样来避免数据冒险。 虽然这一机制实现起来相当简单,但是得到的性能却并不好,一条指令更新一个寄存器,紧随其后的指令使用被更新过的寄存器的事情非常普遍,为了保证正确的执行,在其中不断的加入nop,导致流水线暂停长达三个周期,这严重的降低了 整体的吞度量。
- 转发来避免冒险: 将结果直接从一个流水线阶段传到较早阶段的技术称为 数据转发, 也就是较早的反馈到需要的阶段。比如 译码阶段。
- 控制逻辑的特殊处理: 控制逻辑的优化,有些繁杂,需要结合 时钟周期、代码执行阶段来 具体分析。
- 未考虑的方面:
- 多周期指令,一些复杂的操作 例如乘法、除法。一种方法是 同步到特殊单元来进行处理,流水线继续处理其他指令(并发执行)。但是不同的单元操作需要是同步的,以避免 出错。
- 存储器接口: 涉及到存储器的命令,具体来说是 是以存储器位置的虚拟地址来引用他们,这涉及到, 地址翻译(将虚拟地址翻译成物理地址),然后对存储器进行操作。在有些情况,被引用的存储器位置储存在硬盘上,硬件会产生一个 缺页 异常信号,这个异常会导致处理器调用操作系统的缺页代码,然后访问磁盘数据到高速缓存中,访问 磁盘就需要数百万个 时钟周期。所以其导致的性能下降是非常严重的。
- 总结
- ISA指令集结构,提供了代码到处理器具体实现的一层抽象。也就是一条指令执行完了,下一条指令执行。
- 流水线化 通过让不同的阶段并行操作,改进了系统的吞度量性能,然而我们必须小心,以便流水线化 执行与程序的顺序执行得到相同的程序行为。
- 拆分指令为阶段:
优化程序性能
- 代码标准:
- 清晰简洁的代码,能够很容的理解代码。
- 运行的快(比如实时处理视频帧,网络包)
- 如何编写高效率的代码:
- 组合正确的数据结构和算法,
- 需要编写出编译器能够有效优化以转换成高效可执行代码的源代码。对于第二点,理解编译器的能力和局限性是非常重要的
- 并行计算
在算法级别上, 几分钟就能编写一个插入排序,而搞笑的是排序算法程序可能需要一天或更长的时间 来实现和优化,在代码级上, 许多低级别的优化往往会降低程序的可读性和模块性,是的程序容易出错,并且难以修改和扩展,对于在性能重要的环境中反复执行的代码,进行广泛的优化比较合适。一个挑战就是尽管做了广泛的优化,但还是要维护代码一定程度的简洁和可读性。一个很有用的策略是,只写到编译器能够产生有效代码的程度就好了。
- 程序优化:
- 消除不必要的内容,让代码尽可能有效的执行期望的工作。这包括不必要的函数调用,条件测试,存储器引用。并且这些是不依赖于目标环境的(思想通用)
- 利用处理器提供的指令级表示进行优化。
- 编译器的局限性
int f(); int func1(){ return f() + f() + f() + f(); } int func2(){ return f() * 4; } int counter = 0; in func1(){ return counter ++; }func1 函数具有副作用,他修改了程序状态的一部分,改变了整体程序的行为,大多数编译器不会试图判断一个函数是否具有副作用,所以,编译器会保持函数调用不变, 并不会按照人们预期的 进行函数调用优化
-
另一个示例
消除循环的低效率代码; 例如for(i = 0; i< strlen(s); i++) 中,strlen的调用,我们可能会假想strlen函数只调用一次,然而编译器并不会这么做,他假定每次strlen的函数调用是不同的。从而在每次循环中多增加了一次函数调用。示例说明一个问题: 一个看上去无足轻重的代码片段有隐藏的渐进低效率,通常人们会在一个小的数据集中进行测试和分析程序,对此程序的性能是足够的。不过, 当程序最终部署好以后,过程完全可能应用在一个100万个字符串上。突然,这段无危险的代码变成了程序的主要性能瓶颈。大型编程项目中出现这样的问题的故事比比皆是。一个有经验的程序员工作的一部分就是避免引入这样的渐进低效率。
这个优化是常见的一类优化例子: 代码移动, 这类优化包括识别要执行的多次但是计算结果不会改变的计算。因而可以将计算移动到代码前面不会被多次求值的部分,编译器会试图进行代码移动,他们不能够发现一个函数是否会有副作用,因而假设函数会有副作用。所以,程序员经常需要显示的完成代码移动。
-
- 手动优化的几个建议:
- 减少过程调用: 一个纯粹主义者可能会说这种变换严重损害了程序的模块性。比较实际的程序员会争辩说 这种变换是获得高性能结果的必要步骤。对于性能至关重要的应用来说。为了速度,经常必要的损害一些功能模块性和抽象性,为了防止以后修改代码,添加一些文档是很明智的,说明采用了那些变换以及导致这些变换的假设。
- 消除不必要的存储器引用
- 循环展开: 一种程序变换, 通过增加每次迭代计算的元素数量,减少循环的迭代次数,循环展开能够从两方面改善程序的性能。 1. 减少 不直接有助于程序结果 的操作的数目, 例如循环索引计算和条件分支 2. 提供了一些方法,有助于减少整个计算中关键路径上的操作数量。
- 提高并行性: 程序是受运算单元的延迟限制的。执行加法和乘法的功能单元 是完全流水线化的。这意味着他们可以每个时钟周期开始一个新操作。代码不能利用这种能力。即使是使用循环展开也不能,这是因为我们将积累值放在一个单独的变量acc中,在前面的计算完成之前,都不能计算acc的新值。打破这种顺序关系是问题的关键。1, 多个累积变量。 2. 重新结合变换。减少计算中的关键路径上的操作数量。通过更好地利用功能单元的流水线能力得到更好点性能,大多数编译器不会对浮点数做重新结合,因为这些运算是不符合结合律的。通常我们发现, 循环展开和并行的积累在多个值,是提高程序性能的更可靠的方法。
- 分支预测和预测错误的处罚: 书写适合用条件传送实现的代码。分支预测错误,会招致严重的处罚
- 存储器性能: 只考虑所有的数据都存放在高速缓存中的情况。(在下一章节中,进行详细的介绍)
- 对循环展开和多个累计变量,重新结合变化的代码示例
void combine4(vect_ptr v, data_t * dest) { long int i; long int length = vect_length(v); data_t * data = get_vec_start(v); data_t acc = 1; for (i = 0; i < length; i ++){ acc = acc * data[i]; } * dest = acc }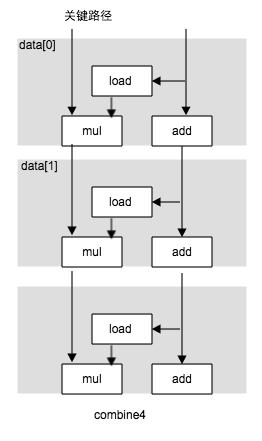
void combine5(vec_ptr v, data_r * dest) { long int i; long int length = vect_length(v); long int limit = length - 1; data_t * data = get_vec_start(v); data_t acc = 1; for(i = 0; i < limit; i+=2){ acc = (acc * data[i]) * data[i+1]; } for (; i< length ; i++){ acc = acc * data[i]; } * dest = acc; }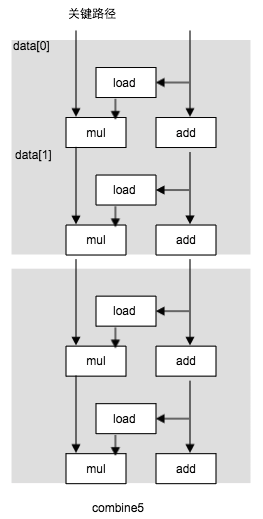
void combine6(vec_ptr v, data_r * dest) { long int i; long int length = vect_length(v); long int limit = length - 1; data_t * data = get_vec_start(v); data_t acc0 = 1; data_t acc1 = 1; for(i = 0; i < limit; i+=2){ acc0 = acc0 * data[i]; acc1 = acc1 * data[i + 1]; } for (; i< length ; i++){ acc = acc0 * data[i]; } * dest = acc0 * acc1; }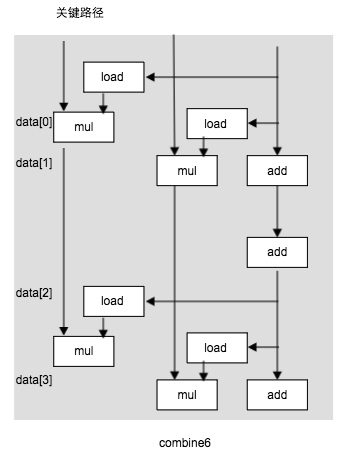
void combine7(vec_ptr v, data_r * dest) { long int i; long int length = vect_length(v); long int limit = length - 1; data_t * data = get_vec_start(v); data_t acc = 1; for(i = 0; i < limit; i+=2){ acc0 = acc * (data[i] * data[i + 1]; } for (; i< length ; i++){ acc = acc * data[i]; } * dest = acc; }```
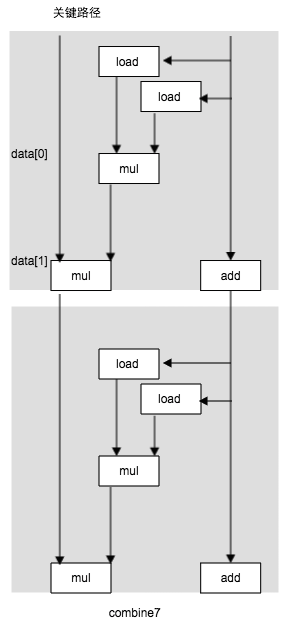
- 总结 优化程序效率的层次以及方法:
- 高级设计: 选择恰当的算法和数据结构,避免使用那些会渐进的产生糟糕的性能的算法和编码技术
- 基本编码原则:避免限制优化的因素
- 消除连续的函数调用。在可能时,可以牺牲模块性来获得更大的效率
- 消除不必要的存储器引用: 引入临时变量来存储结果,只在 最后的时候,将结果存放到数组变量、全局变量中
- 低级优化
- 展开循环
- 多个累积变量 和重新结合的技术,找到方法提高指令级别的并行(利用指令的流水线化)
- 用功能的风格重新条件操作,使编译器采用条件数据传送。
- profiling
警惕在优化效率时候引入错误,引入新变量,改变循环边界 使得代码整体上更为复杂,很容易导致错误,需要测试来保证优化代码的正确性。
存储器层次结构
- 认识存储器系统
- 存储器系统: 是一个具有不同容器、成本和访问时间的存储设备的层次结构,CPU寄存器保存最常用的数据,高速缓冲区作为一部分存储在相对慢速的主存储器中的数据和指令的缓冲区, 主存暂时存放存储在容量较大、慢速的磁盘上的数据,而磁盘常常作为存储在通过网络连接的其他机器的磁盘上的数据的缓冲区。
- 存储器层次结构: 对应用程序的性能有着巨大的影响,CPU寄存器中的数据在0个周期可以访问,在高速缓冲中1-30个周期,主存中50-200个周期,如果存储在磁盘上,大概需要 几千万个周期。
- 存储器层次结构是可行的,一个编写良好的程序倾向于频繁的访问某一个层次上的存储设备。存储器实现的整体效果是,其成本与层次结构底层最便宜的存储设备相当。 但是却以最接近于层次结构顶部存储设备的高速率向程序提供数据。
- 局部性: 一个计算机程序的基本属性。具有良好局部性的程序倾向于一次又一次的访问相同的数据项集合。或是倾向于访问邻近的数据项集合。具有良好局部性的程序比局部程序差的程序更倾向于访问更高层次的数据项,其运行速度也可以相差20倍。
- 存储技术:
- 静态RAM: SRAM, 双稳态特性。
- 动态RAM:DRAM, DRAM 存储器单元对干扰非常敏感,暴露在光线之下会导致电容电压的改变,数据照相机摄像机中的传感器本质就是DRAM,DDR(2 位), DDR2(4位), DDR3(8位)双倍数据速率同步DRAM, (Double Data-rate Synchronous)
- 总线: 数据通过总线 共享电子电路在处理器和DRAM主存之间来来回回,每次CPU和主存之间的数据传送都是通过一系列步骤来完成的。这些步骤通过总线事务。总线是一组并行的导线, 能携带地址、数据、控制信号。控制总线携带的信号会同步事务,并区分当前正在被执行的事务类型。例如, 当前得儿事务是主存,还是磁盘,以及其他磁盘设备,信息是地址,还是数据,事务是读还是写。
- 总线接口 — I/O桥 —— 主存, I/O桥将系统总线的信号翻译成存储器总线的电子信号。
- 磁盘存储, 画图
- 固态硬盘(Solid State Disk SSD) ssd 的性能特性, 顺序读和写性能相当,顺序℃比顺序写稍微快一点,但是按照随机顺序访问逻辑快时, 写比读慢一个数量级。一个闪存是由B个块的序列组成。每个块有P页组成,通常页的大小是512-4Kb, 块是32-128页组成的。树蕨是以页单位读写的。只有一页所属的真个块被擦除之后,才能写这一页,不过一旦一个块被擦除了,块中每一个都可以不需要在进行擦除就可以写了,大约在100000次重复写之后,块就会损坏。速记写慢的原因: 1. 擦出块需要相对较长的时间,1ms级别,比访问页所需时间要高出一个数量级,2. 如果写操作试图修改一个包含已经有数据的页,那么这个块中所有有用数据的页都必须拷贝到一个新块,才能进行对页p的写。
- 局部性:
一个编写良好的程序具有良好的局部性, 他倾向于引用邻近其他最近引用过的数据项的数据,或者最近应用过的数据项,这种倾向性被称为局部性原理。1. 时间局部性, 2. 空间局部性- 时间局部性: 被引用一次的存储器位置很可能在不远的将来再被多次引用。
- 空间局部性: 一个存储器位置被引用了,那么程序很可能在不远的将来引用附近的一个存储位置
int sumec(int v[N]) { int i, sum = 0; for(i = 0 ; i < N ; i++) { sum += v[i]; } return sum; }空间局部性很好, 时间局部性很差, 在一个连续的向量模式中,每隔k个元素进行访问, 就被称为步长为k的引用模式,一般而言,随着步长的增加, 空间局部性下降。
- 存储器层次结构
图片- 缓存命中:
- 缓存不命中:
- 第k层的缓存从第k+1缓存中 取出包含的那个块,如果k层的缓存已经满了的话,就需要覆盖现存的一个块。 成为替换或驱逐这个块,倍驱逐的这个块儿,称为 牺牲块,决定该替换那个块是有缓存的替换策略来控制的。比如随机替换策略和最近最少被使用的(LRU)替换策略
- 缓存不命中的种类: 冷缓存: 一个空的缓存,他是短暂的事件,不会在反复访问存储器是的缓存暖身之后的稳定状态中出现。2. 只要发生了不命中,k层的缓存就必须执行某个放置策略,确定它从第k+1层中的数据放在哪里。
- 冲突不命中: 被引用的数据对象,映射到同一个缓存块,缓存会一直不命中
- 容量不命中: 一个嵌套的循环可能会反复的访问同一个数组的元素,这个块的集合称为这个阶段的工作集,当工作集的大小超过了缓存的大小,就会发生 容量不命中的
链接
TODO
链接 是将各种代码和数据部分收集起来并组合成为一个单一文件的过程,链接可以执行于 编译时(compile time 也就是在源代码被翻译成机器代码时)也可以执行于加载时(load time在程序倍加载器加载到存储器并运行时)甚至执行于运行时(run time 有应用程序来执行)
链接器 在软件开发中,扮演者一个关键的角色,因为他们使得的分离编译 成为可能,我们不用将一个大型的应用程序组织为一个巨大的源文件,而是可以把她分解为更小,更好管理的模块,可以独立的修改和编译这些模块。当我们修改一个文件时候,简单的编译她,并重新连接应用,而不必重新编译整个项目。
链接器产生的可执行文件在重要的系统功能中扮演者重要的角色,比如 加载和运行程序,虚拟存储器,分页,和存储器映射。随着共享库和动态连接在 操作系统中的重要性加强,链接成为一个复杂的过程。linux elf目标文件格式。
异常控制流
异常控制流(ExceptI/Onal Control Flow ECF): 异常控制流发生在计算机的各个层次。
硬件层: 硬件检测的事情会触发控制突然转移到异常处理程序
操作系统层: 内核通过 上下文切换 将控制从一个用户进程转移到另一个用户进程
应用层面: 一个进程可以通过发送信号到另一个进程, 而接受者将转移到信号处理程序
- 异常控制流:
- 是操作系统用来实现I/O、进程、和虚拟存储器的基本机制
- 是应用程序与操作系统交互的方式: 应用程序通过一个陷阱(trap)或 系统调用(system call) 的形式,向操作系统请求服务。
- 操作系统为程序提供了强大的ECF机制,创建进程、等待进程、通知其他进程系统中的异常事件等
- ECF是计算机实现并发的基本机制
- 提供程序方面的异常机制,try, catch。 setjmp, longjmp)
- 异常:
- 异常是异常控制流的一种形式。
- 实现: 硬件 + 操作系统, 随着系统不同而不同,但是基本思想相同,
- 控制流中的突变, 用来响应处理器状态中的某些变化。也称为事件, 比如: 发生虚拟存储器缺页,算数溢出, I/O请求完成等。
- 事件放生时候, 处理器通过 异常表(exceptI/On table, 间接跳转表) 来调用 操作系统子程序—异常处理程序(一个专门设计来处理这种事件的操作系统子程序)
- 异常处理类似于函数调用, 但是不同于函数调用:
- 异常处理程序运行在内核模式下,这意味着他们对所有的系统资源都有完全的访问权限
- 如果控制从一个用户态转到内核态,那么所有的项目都需要压到内核栈中
- 过程调用, 在跳转到程序之前,处理器将返回地址压倒栈中, 异常:返回地址要么是当前指令,要么是 下一台指令。
- 异常类型: 中断(interrupt), 陷阱(trap), 故障(fault)终止(abort)
- 中断: 来自处理器外部的I/O设备的信号的结果, 异步, 硬件中断的异常处理程序 通常称为 中断处理程序。
- 陷阱: 有意的异常,是执行一条指令的结果。陷阱的重要用途是: 在用户程序和内核之间提供一个像过程一样的接口,叫系统调用。 从程序员的角度来看, 系统调用和函数调用是一样的,然而其中的内部实现是非常不同的。 普通的函数运行在用户模式中, 用户模式限制了函数可以执行的指令的类型
- 故障: 由错误引起的,故障发生时, 处理器将控制转移到故障处理程序,如果处理程序能够处理修正错误,他将控制权转移到引起故障的指令,从而重新执行。否则,处理程序返回到内核中的abort函数,从而终止程序。 一个经典的故障示例是缺页异常, 指令引用的一个虚拟地址,与该虚拟地址关联的物理页面不在 存储器中,从而发生故障。缺页处理程序 从磁盘加载到存储器中之后,将控制权转交到 程序指令, 程序执行再次执行,就不会发生故障了。
- 终止: 是不可以修复的致命错误造成的结果, 通常是一些硬件错误。终止处理程序,不会将控制返回到应用程序,而是终止应用程序。
- linux 中的异常示例:
-
linux 故障和终止:
异常号 描述 异常类型 0 除法错误 故障 13 一般保护故障 故障 14 缺页 故障 18 机器检查 终止 32-127 操作系统定义的异常 中断或陷阱 128 系统调用 陷阱 129-255 操作系统定义的异常 中断或陷阱 - linux 系统调用: 每个系统调用都有一个唯一的整数号, 对应于一个到内核中的跳转表的偏移量。
- 系统调用是通过 指令 int 0x80 调用的, 参数传递都是通过寄存器而不是栈传递的。 %eax为系统调用号, 寄存器%ebx, %ecx …为调用参数, 标准C函数库提供了包装函数, 这些包装函数将参数打包在一起, 以适当系统调用号陷入内核。然后将系统调用的返回状态传递给调用函数,完成包装任务。
-
- 进程:
- 一个执行中的程序的示例。 系统中的每个程序都是运行在某个进程的上下文中的。上下文是程序正确运行所需要的状态的组成。包括, 程序代码和数据,栈,通用寄存器的内容,程序计数器等
- 异常是允许 操作系统提供进程的概念所需要的基本构造块。
- 在外壳程序中输入可执行目标文件的名字, 外壳会创建一个新的进程,然后在这个进程的上下文中 运行这个可执行目标文件。
- 进程提供的关键抽象有:
- 一个独立的逻辑控制流,提供一个独占使用处理器的假象
- 一个私有的地址空间,提供一个独占存储系统的假象
- 并发与并行:
- 逻辑控制流:因为进程提供每个程序单独使用处理器的假象。所以程序计数器(PC)的值的序列叫做 逻辑控制流
- 并发: 并发流(concurrent)一个逻辑控制流 的执行时间 与另一个逻辑控制流重叠, 称为并发的执行。多个流并发的执行称为并发,
- 一个进程与其他进程轮流运行成为多任务
- 并行流(parallel follow) 是并发流的一个真子集, 如果两个流并发的运行在不同的处理器核或者计算机上,我们称为并行流,
- 私有地址空间: n为地址的机器上, 0,1,2……z**n - 1, 地址空间顶部是保留给内核的,该部分是内核在代表进程执行指令时使用的代码,数据和栈
- 用户模式、内核模式:
- 为了提供一个无懈可击的进程抽象,处理器提供一种机制,来限制一个应用可以执行的指令以及他可以访问的地址空间。( 为了一个无懈可击的抽象?还是因为安全, 比如内核模式应该可以对用户模式,掩盖 地址抽象的细节,而不是,让用户破坏这种抽象)
- 一般是处理器通过一个寄存器中的一个模式位(mode bit)来提供这种功能的。该寄存器 描述了进程当前的特权, 设定了位模式, 进程在内核模式,反之在用户模式
- 内核模式: 一个运行在内核模式中的程序可以执行指令集中的任何指令,并可以访问系统中的任何存储位置。
- 用户模式: 不允许执行执行特权命令,比如:停止处理器, 发起一个I/O操作。
- 进程进入到内核模式的唯一方法是:通过,中断、故障、或者陷入(系统调用)来进入到内核模式。
- 上下文切换:
- 上下文切换: 操作系统通过这种较高层次的异常控制流来实现多任务。上下文切换机制是建立在 中断,陷阱,故障,终止 较低异常层次机制之上的。
- 上下文: 就是内核重启一个被抢占进程所需要的数据状态。包括,寄存器,程序计数器,内核栈,和各种数据结构等。内核为每一个进程提供一个上下文。
- 调度: 在进程执行的某些时刻(那些?),内核可以决定抢占 当前进程,并重新开始一个进程, 这种决定叫做调度。有内核中成为调度器的代码处理。在内核调度了一个进程运行后,她就抢占了当前进程,使用上下文切换机制来将控制转移到新的进程。
- 保存当前进程的上下文
- 恢复某个先前被抢占的进程被保存的上下文
- 将控制转移到新的进程
- 上下文切换的几个简单示例:
- 中断(任何时候): 所有系统都有某种产生周期性定时器中断的机制,典型的为1毫秒, 每次发生定时器中断时,内核就能够判断 当前进程是否执行了足够的时间,并切换到一个新的进程。(操作系统赖以生存的控制机制)
- 阻塞:系统调用时候,因为等待某个事件而发生阻塞,可能发生上下文切换。比如 read 系统请求磁盘访问,内核可能进行上下文切换, 来执行其他操作,而不是等待I/O, Sleep 系统调用, 显示的请求让调用进程休眠。
- 进程控制:
- 进程创建和终止: 从程序员的角度来看 进程总是处于3个状态: 运行, 停止,终止,
- 停止: 进程的执行被挂起。 且不会被调度, 当收到SIGSTOP, SIGTSTP, SIDTTIN, SIGTTOUT 进程就会停止,并保持停止直到它收到一个SIGCONT 程序再次执行
- 终止: 进程永远停止。原因有: 1. 收到一格信号,该信号默认行为是终止进程 2. 从主程序返回 3. 调用exit函数
- fork
- 子进程得到与父进程用户级虚拟地址空间相同的 一份拷贝, 文本,数据,bss,堆等。 子进程还获得父进程任何打开文件描述符的相同的拷贝。 这意味子进程可以读写父进程中打开的任何文件。最大的区别在于PID。
-
fork函数 只被调用一次, 却返回两次。在父进程中 fork返回子进程的PID, 在子进程中,返回0,因为子进程的PID为非零,所以提供了一种明确的方法,来分辨程序在 父进程中,还是子进程中执行。
int main() { pid_t = pid; int x = 1; pid = Fork(); if (pid == 0){ printf("child :x %d\n", ++x); exit(0); } printf("parent: x %d\n", --x); exit(0); } - 调用一次返回两次: fork函数被父进程 调用一次, 但是却返回两次, 一次返回到父进程中,一次返回到子进程中,对于只fork一次的程序来说,这还是相当简单直接的,但是对于多次fork的程序来说,需要谨慎的分析
- 并发执行:父进程和子进程是并发运行的独立进程。也就说不能够假定 进程的执行顺序。
- 相同的但是独立的地址空间
- 共享文件:子进程继承了父进程的所有的打开文件。
- 回收子进程:wait/waitpid
- 回收: 当一个进程终止时,内核并不是把它从系统中清除出去,而是保持终止状态,直到父进程回收。当父进程回收已经终止的子进程时,内核将子进程的退出状态传递给父进程。然后抛弃已终止的进程。改进程就不存在了,
- 僵死进程: 一个终止了但是还没有被回收的进程,
- 僵死进城处理: 父进程还没有回收僵死进程就退出了,那么内核会安排init进程来回收他们。init 进程PID 为1在系统初始化时候有内核创建。
- waitpid 函数
- waitpid(pid_t pid, int * status, int optins)
- pid > 0 等待单个pid, pic = -1, 等待 父进程的所有子进程。
- optI/Ons:
- WNOHANG: 等待集合中的任何子进程都还没有终止, 那么就立即返回, 默认行文是 挂起调用进程, 直到所有子进程终止,
- WUNTRACED: 挂起调用进程, 直到 等待集合中一个进程变成 已终止或者被停止,返回, 返回的PID为引起返回的 进程PID, 默认行为:返回已经终止的子进程
- WHOHANG | WUNTRACED, 立即返回, 如果等待集合中没有任何子进程被停止或已终止, 那么返回值为0, 或者返回那个停止的终止的进程PPID
- 如果status参数非空,waitpid在status中放置 关于导致返回子进程的状态信息。下面是解释status参数的几个宏
- WIFEXITED(status): 如果子进程通过调用exit或者一个返回(return) 正常终止。就返回真
- WEXITSTATUS(status): 返回一个正常终止的子进程的退出状态,只有在WIFEXITED 返回为真时了, 才会定义这个状态。
- WIFSIGNALED(status): 如果子进程是因为一个未被捕获的信号终止的。那么返回真
- WTERMSIG(status): 返回导致子进程终止的信号的编码, 只有咋WIFESIGNailed为真 才定义这个状态
- WIFSTOPPED(status): 如果引起返回的子进程当前是被停止的。那么就返回真。
- WSTOPSIG(status): 返回引起子进程停止的信号的数量,只有 wifstopped 返回为真时,才定义这个状态。
- wait 函数是waitpid 的 简单版本, wait(int * status) === waitpid(-1, & status, 0)
- 让进程休眠
- sleep:休眠一定秒数
- pause:函数让调用进程休眠,直到该进程收到一个信号
- 加载并运行程序 execve:
- execve(char * filename, char * argsv[], char * envp[])
- 函数加载并运行可执行目标文件filename, 并传递参数argv, 环境变量 envp execve 调用一次 并不返回 fork函数在新的子进程中运行相同的程序,新的子进程是父进程的一个复制品。 execve 函数在当前进程的上下文中加载并运行一个新的程序,他会覆盖当前进程的地址空间。但是并没有创建一个新进程。新进程依然有相同的PID, 已打开的文件描述符
- 进程创建和终止: 从程序员的角度来看 进程总是处于3个状态: 运行, 停止,终止,
- 信号
- 信号概念
- 更高层的软件异常形式。允许中断其他进程
- man 7 signal 得到信号列表
- 每个信号类型都对应于 某种系统事件, 底层的硬件异常 是由内核异常处理程序处理的。正常情况下, 对用户进程是不可见的。信号提供了一种机制,来通知用户发生了这些异常。
- 发射信号 到接受者的过程 相关概念:
- 发送信号: 内核通过更新目的进程的上下文中的某个状态,来发送一个信号到目的进程,发射信号的原因有: 1. 内核检测到一个事件,通知进程, 2. 一个进程调用kill函数, 要求内核发送信号。
- 接受信号: 当目的进程被内核强迫以某种形式对信号的发送做出反应时,反应有: 1. 忽略信号, 2. 终止 3. 执行信号处理程序的用户函数
- 待处理信号:一个发出而没有被接受的信号,任何时刻, 一种类型至多只会有一个待处理信号。如果一个进程有一个类型为k的待处理信号,那么任何接下来的发送到进程的类型为k的信号,都会被简单的丢弃。
- 阻塞信号: 一个进程可以设定阻塞一种类型的信号。可以被发送,但是不会被接受。
- 实现: pending 位向量 维护待处理信号集合, blocked 位向量,维护被阻塞信号集合。传递类型为k的信号, pending 的k位 被标记, 接收了 清除标记。
- 发送信号
- 进程组: 提供了大量向进程发送信号的机制, 所有这些机制都是基于进程组的。每个进程都属于一个进程组,
- kill 程序发送信号
- 键盘发送信号, 外壳程序 创建程序执行,ctrl-c 会发送一个SIGINT信号到 外壳, 外壳程序捕获到该信号,然后发送SIGINT 信号到这个前台进程中的每个进程。ctrl-z则会发送 SIGTSTP 信号
- kill 函数调用
- alarm 函数发送信号 SIGALRM 信号, 在sec 秒中发送信号
- 接受信号
- 当内核从一个异常处理程序中返回,准备将控制传递到进程p时,他会检查进程p的未被阻塞的待处理信号的集合。 如果这个集合不为空, 那么内核选择集合中的某个信号k, 并且强制p接受信号k, 触发进程的某个行为, 每个信号类型都有一个预订的默认行为如下:
- 进程终止
- 进程终止并转存储器
- 进程停止知道倍SIGCONT 信号重启
- 进程忽略该信号
- 进程可以通过signal函数修改和信号相关联的默认行为, 唯一的例外是: SIGSTOP, SIGKILL他们的默认行为是不可以修改的。 signal(int signum, sighandler_t handler) 设置信号处理程序选项
- 如果handler 是SIG_IGN, 那么忽略类型为 signum 的信号
- 如果handler 是SIG_DFL,那么类型为signum的信号行为修改未默认
- 否则handler是用户定义的 信号处理程序地址,
- 调用信号处理程序成为捕获信号, 执行信号处理程序为 处理信号。处理程序会调用会传递一个参数k,为信号类型, 因此, 同一个函数可以设定为处理多个信号处理程序
- 设定阻塞,和取消阻塞, sigismember(sigset_t * set, int signum)
- 当内核从一个异常处理程序中返回,准备将控制传递到进程p时,他会检查进程p的未被阻塞的待处理信号的集合。 如果这个集合不为空, 那么内核选择集合中的某个信号k, 并且强制p接受信号k, 触发进程的某个行为, 每个信号类型都有一个预订的默认行为如下:
- 信号处理问题:
- 待处理信号被阻塞: Unix信号处理程序通常会阻塞当前处理程序正在处理类型的待处理信号。如果一个进程捕获一个SIGINT信号,并运行处理程序,如果另外一个SIGINT 信号传递到这个进程, 那么这个SIGINT将变成待处理的,但是不会被接受,直到处理程序返回
- 待处理信号不会排队等待,任意类型至多只有一个待处理信号
- 系统调用可以被中断,慢系统调用, read, wait, accept等会阻塞进程一段时间,某些系统中当捕获一个信号时,被中断的慢系统调用不会被继续而是返回错误
- 非本地跳转: 它将控制直接从一个函数转移到另一个当前正在执行的函数,而不需要经过正常的调用–返回序列。(setjump longjump, sigsetjmp, siglongjmp)
- setjump 函数在env 缓冲区中保存当前调用环境
- longjmp 从env缓冲区中恢复调用环境,然后触发一个从最近一次初始化env的setjmp调用的返回,然后setjmp返回,并带有非零的返回值retval
- 从深层嵌套函数调用中立刻返回
- 信号处理程序分支到一个特殊的代码位置,而不是返回到倍信号到达中断了的指令位置
- C++, java提供的异常机制是较高层次的,是C语言的setjmp, longjmp更结构化的版本。
- 信号概念
- 总结
- 异常控制流发生在计算机系统的个个层次,是计算机系统中提供并发的基本机制
- 硬件层面, 异常是有处理器中的事件 触发的控制流突变。控制流传递给一个软件处理程序,止呕返回给被中断的控制流
- 异常类型: 中断 故障 终止 陷阱
- 在操作系统层面, 内核用ECF 提供进程的基本概念
- 在应用层面, C语言使用分本地跳转来规避正常的调用、返回栈 规则(try catch 等的实现类似)
虚拟存储器
TODO
系统级 I/O
I/O 主要在主存和外部设备之间拷贝数据的过程, 输入操作是从I/O 设备拷贝数据到主存, 而输出操作是从主存拷贝数据到 I/O设备
- I/O
- 是系统中不可或缺的一部分,经常会遇到I/O和其他系统概念循环依赖的情景:I/O 在进程的创建和执行扮演着关键角色,反过来,进程创建在不同进程间的文件共享中扮演关键角色。
- 所有的I/O设备,如网络、磁盘、终端 都被模型化为文件。而所有的输入和输出都被当做对应的文件的读写操作。这种将设备优雅的映射为文件的方式,允许Unix内核引出一个简单的低级的应用接口,成为Unix I/O, 这使得所有的输入和输出都以统一、一致的方式来执行。
- 操作
- 打开文件: 用程序通过 要求内核打开相应的文件,来访问一个I/O设备, 内核返回一个小的非负数的描述符。后续的操作都通过这个描述符
- seek: 改变当前的文件位置, 对于每个打开的文件,内核保持着一个文件位置k,标志着从文件开头起始的字节偏移量。seek操作可以显示的设定位置
- 读写文件: 读操作就从文件拷贝 n > 0个字节,k 为当前文件位置, m 为文件大小, k+n >=m 的操作,会触发一个end-of-file(EOF) 的条件。应用程序能够检测到这个条件, 在文件结尾处并没有明确的 “EOF” 符号。
- 关闭文件: 当应用完成了文件的访问之后, 他通知内核关闭这个文件。内核释放文件打开时创建的数据结构,并将描述符恢复到可用的描述符池中。无论一个进程因为什么原因终止,内核都会关闭所有打开的文件并释放存储器资源。
- 共享文件
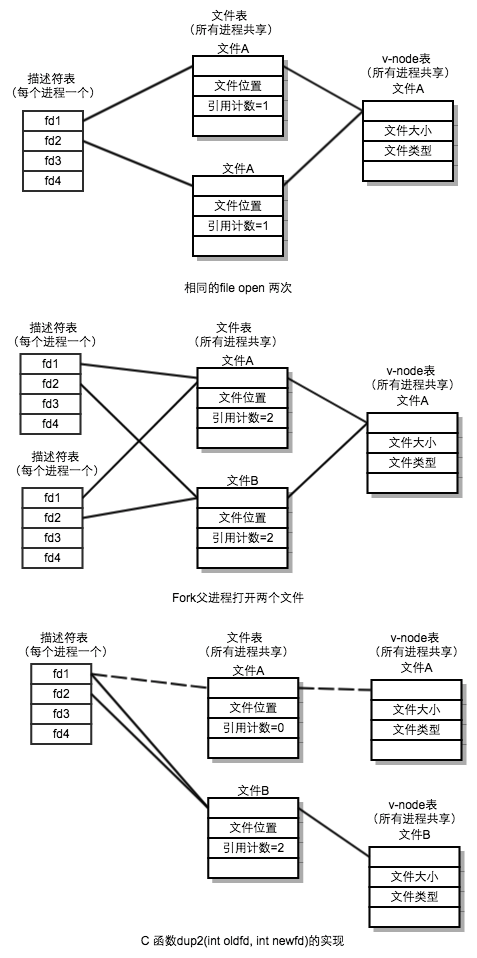
- 描述符表(descriptor table):
- 每个进程都拥有独立的描述符表
- 描述符: 每个打开的描述符索引 文件表 中的一个表项
- 文件表(file table):
- 所有的进程共享
- 所有的打开的文件的集合组成的 文件表
- 文件表项 包括当前的文件的位置、引用计数、以及一个指向 v-node 表中对应表项的指针
- 关闭一个描述符会减少响应的文件的表 表项中的引用计数。为零时,内核会删除表项
- v-node 表:
- 所有的进程共享
- 包含文件的大多数信息。包含st_mode, st_size 等成员,
- todo, 补充文件元信息的数据结构
- 描述符表(descriptor table):
- 场景
- 打开同一个file 两次, 会产生, 两个文件表表项, 来标注两个文件不同的文件位置,引用计数等。
- fork: 子进程会copy 一个 父进程描述符表表项的副本,指向相同的 文件表表项。所以子进程跟父进程共享同一个文件位置,增加文件引用计数。
- 总结
unix 提供了少量的系统级别函数, 他们允许应用程序打开、关闭、读和写文件、提取文件的元数据,以及执行I/O重定向。Unix内核使用三个相关的数据结构来表示打开的文件。描述符表项指向文件表表项, 文件表表项指向v-node 表项,每个进程都有自己的描述符表项,所有进程共享 文件表和v-node表。理解这些数据结构,利于,理解,fork, 已经I/O重定向的实现。标准I/O库是基于UnixI/O实现的,标准I/O更简单,优于unix I/O, 因为对标准I/O和网络文件一些相互不兼容的问题,Unix I/O 更适合网络应用程序
网络编程
网络应用随处可见,web浏览器,email,wechat,有趣的是,所有的网络应用都是基于相同的基本编程模型,有着相似的整体逻辑结构, 并且依赖相同的编程接口。
网络应用依赖于许多概念: 进程、信号、字节序列、存储器映射以及动态分配存储, 都扮演者重要的角色
- 套接字:
客户端和服务器 混合使用套接字接口函数和 Unix I/O函数来进行通讯,套接字函数典型的是作为会陷入内核的系统调用来实现。并调用各种内核模式和TCP/IP 函数
- int socket(int domain, int type, int protocol)
- int connect(int sockfd, struct sockaddr, int addrlen): 客户端通过调用 connect 函数 建立服务端的连接, connect函数会阻塞,一直到成功建立连接,或是发生错误,如果成功, sockfd 描述符可以进行读写了, 并且得到连接套接字对(x:y, serv_addr,:serv_addr.sin_port) x表示客户端的ip地址,y表示临时窗口,他唯一确定了客户端主机上的进程
- bind(int sockfd, struct sockaddr * my_addr, int addrlen): bind函数告诉内核将my_addr中的服务器套接字地址和套接字描述符sockfd联系起来
- listen(int sockfd, int backlog): 服务器调用listen函数告诉内核, 描述符是被服务器而不是客户端使用的。listen函数将sockfd 从一个主动套接字转化为一个监听套接字(listening socket) 该套接字可以接受来自客户端的连接请求,backlog 表示内核在开始拒绝请求之前, 应该放入队列中等待的未完成连接的请求的数目。backlog参数的确切含义要求退TCPIP协议的理解。
- accept(int listenfd, struct sockaddr * addr, int * addrlen): accept函数等待客户端到达listenfd的连接请求,然后在addr中填入客户端的套接字地址,并返回一个已连接描述符(connected descriptor)这个描述符 可以使用unix I/O进行操作与客户端通讯
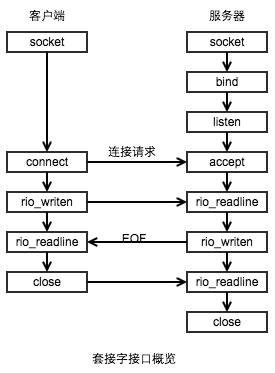
- 监听描述符和已连接描述符的区别:
- 监听描述符: 是作为客户端连接请求的一个端点, 创建一次, 并存在于服务器的整个生命周期
- 已连接描述符: 是客户端与服务端已经建立连接起来的一个端点。服务器每次接受请求都会创建一次,他只存在于服务器为一个客户端服务的过程中
- 然而区分: 这两者, 被证明是很有用的。因为他使得我们可以简历并发服务器,他能够同时处理许多客户端连接,例如,每一个请求到达监听描述符时, 我们可以fork一个进程去处理,他可以通过已连接描述符对客户端进行通讯,
- HTTP
- Web服务器, web客户端和服务器之间的交互是一个基于文本应用级协议,叫做HTTP, 其内容是一个与Mime(multipurpose internet Mail ExtensI/Ons 多用途网际邮件扩充协议)类型关联的字节序列。
MIME 类型 描述 text/html HTML 页面 text/plain 无格式文本 applicatI/On/postscript postscript 文档 image/gif gif 格式编码的图片 image/jpeg jpeg格式编码的图片
- 服务动态内容: 客户端如何将程序参数传递给服务器, 服务器如何将这些参数传递给 他所创建的子进程? 子进程 将他的输出发送到哪里?一个成为CGI(common Gateway Interface) 通用网关接口的实际标准解决了这些问题。
- 客户端如何将程序参数传递给服务器: ?, &分割开来
-
服务器如何将参数传递给 子进程: CGI设定环境变量 QUERY_STRING=name=xx&age=xxx, 子进程可以通过getenv函数获得
环境变量 描述 SERVER_PORT 父进程监听的port QUERY_STRING url 参数 REQUEST_METHOD get or post etc REMOTE_HOST 客户端域名 REMOTE_ADDR 客户端ip CONTENT_TYPE 请求体的MIME CONTENT_LENGTH 请求体的大小 - 子进程将输出到哪里? 一个CGI程序将动态内容发送到标准输出, 在子进程加载并运行CGI程序之前, 使用unix dup21将标准输出重定向到客户端相关的已连接描述符。 因为CGI程序小入到标准输出的东西,会直接送到客户端。
并发编程
逻辑控制流在时间上重叠,就称为并发。(concurrency)出现在计算机系统的多个层面上, 硬件异常处理, 进程和Unix信号处理程序
- 应用层面上的并发 在下面的场景非常有用:
- 访问慢速I/O设备, 应用需要等待I/O设备的数据到达时候,内核会运行其他进程,使得CPU保持繁忙。每个应用都可以按照类似的方式,通过交替执行I/O请求和其他有用的工作进行并发
- 服务多个网络客户端: 为每个客户端创建创建一个单独的控制流,允许服务器同时服务多个客户端服务。避免慢速I/O操作独占服务器
- 多个内核机器上的并行计算
- 操作系统提供并发的基本方法:
- 进程: 每个逻辑控制流都是一个进程, 有内核进行维护调度,进程间通讯通过使用显示的进程间通讯(IPC) 机制
- I/O多路复用: 应用程序在一个进程的上下文中显示的调度他们自己的逻辑控制流,逻辑流被模型化为状态机,数据达到文件描述符后,主程序显示的从一个状态转换到另一个状态,因为程序是一个单独的进程,所以所有的流都共享一个地址空间
- 线程: 是运行在一个单一进程上下文中的逻辑流,想进程流一样有内核进行调度,像I/O多路复用一样 共享同一个虚拟地址。
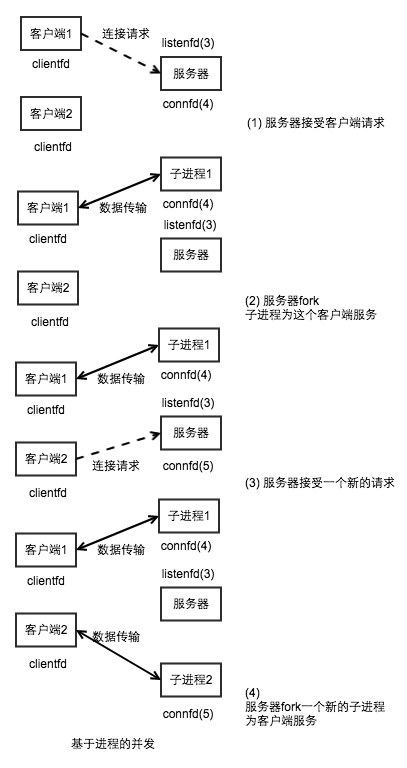
- 基于进程的并发编程:
- 服务器 接受请求之后,父进程fork一个子进程。子进程获得服务器描述符表的完整拷贝。
- 子进程关闭他拷贝的监听描述符, 父进程关闭他的已连接描述符, 因为子父子进程描述符指向同一个文件表表项,所以父进程关闭已连接描述符 是至关重要, 否则, 将永远不会释放已连接描述符的文件表条目,由此引发的存储器泄露 将最终消耗尽所有的存储器,导致系统崩溃 (为什么没有说 子进程关闭 监听描述符呢?以为子进程总是早于 父进程死掉,所以总是可以释放?)
- 父进程回收子进程
- 优劣:
- 非常清晰的并发模型: 共享文件表,不共享用户地址空间。
- 独立的地址空间容易 使得进程共享状态信息变得更加困难。 为了共享信息,需要使用IPC机制, 2. 慢, 进程控制和IPC 的开销太高
- I/O 多路复用并发编程:
- 用来做 并发事件驱动(event-driven) 程序的基础, 在事件驱动程序中,流是因为某种事件而前进的。
- I/O并发模型中的 逻辑流模型 转换为状态, 不严格的说, 一个状态机就是一组状态(state), 输入事件(input event), 和转移(transitI/On) 其中转移就是将输入事件和状态映射到另一个状态。
- 自循环(self loop) 是同一个输入和输出状态之间的转移。
- 服务器使用I/O 多路复用。 select 函数检测输入事件的发生。 当一个已连接描述符准备好读取的时候,服务器作为响应的状态机 执行转移
- 优劣:
- 优点:
- 比基于进程设计的设计给了程序员更多的对程序行为的控制,
- 事件驱动服务器运行在单一的进程上下文中, 因为每个逻辑控制流都能否访问该进程的全部地址空间。这是的在流之间 共享数据变得容易。
- 调试起来变得简单,就像顺序程序一样
- 事件驱动 常常比基于进程的设计的要高效的多,因为他们不需要进程上下文的调度
- 缺点:
- 编码复杂, 不幸的是, 随着并发粒度的减小, 复杂性还会上升,
- 不能够充分利用多核处理器
- 优点:
- 基于线程的并发模型:
- 概念:
- 是运行在进程上下文中的逻辑流, 有内核自动调度,每个线程都有自己的线程上下文, 包括一个唯一的整数线程ID(thread ID TID), 栈,栈指针,程序计数器,etc,
- 基于线程的并发模型是结合 进程、I/O多路复用流的特性。 同进程一样内核自动调度, 同I/O复用一样, 多个线程运行在单一进程的上下文, 因此共享相同的虚拟地址空间, 代码,数据等
- 主线程: 每个进程开始生命周期时候是单一线程,这个线程成为主线程。 然后创建对等线程。 这个时间点开始,两个线程开始并发的执行。然后被 系统进行调度。
- 与进程的不同: 线程的上线文要比进程的上下文小得多。不严格按照父子层次来组织。和一个进程相关的线程组成一个对等(线程池),主线程和其他线程的区别在于他总是进程中的第一个运行的线程,对等线程池的概念的主要影响是: 一个线程可以杀死他的任何对等进程,或者等待他的任何对等线程终止,每个对等线程都能读写相同的共享数据。
- 结合、分离: 在任何一个时间点, 线程是可结合的, 或者是分离的。一个可结合的线程能够被其他线程收回其他资源和杀死。在被其他线程回收之前,他的存储器资源是没有倍释放的。相反。 一个分离的线程是不能被其他线程回收或杀死的。他的存储资源在它终止由系统自动释放。 所以要么显示的回收,要么 pthread_join , pthread_detach. 在现实中,很好的理由要使用分离线程, web浏览器请求时都创建一个新的对等线程, 因为每个连接都是有一个单独的线程独立处理的。 对于服务器而言,就没有必要等待所有的对等线程终止,所以直接使用分离线程,在他们终止之后,资源就自动回收了。
- 多线程序中的共享变量
- 线程存储模型: 线程都有自己的线程上下文, 线程ID, 栈, 栈指针, 程序计数器,条件码 和通用的寄存器,每个线程和其他线程一起共享进程上下文中的其他部分,包括用户虚拟地址空间(制度文本代码, 读写数据,堆,已经所有的共享库代码和数据区域)也同样共享打开的文件集合。
- 变量映射到线程:
- 全局变量: 定义在函数之外,只有一个实例, 任何线程都可以引用。
- 本地自动变量: 定义在函数内,没有static的变量。每个线程栈都包含它自己的所有本地变量的实例。
- 本地静态变量: 函数内部static变量。多个线程共享。
- 同步线程 信号量:
- 为了共享全局数据结构的并发程序的正确执行。
- P(s) : s != 0 那么将s - 1 并返回, 如果s == 0 那么挂起这个线程,直到等待V操作会重启这个线程, p操作继续将S-1,执行。
- V(s) : 将s + 1 , 重启任何一个阻塞的线程。
- 使用信号量, 实现互斥。 应用, 生产者— 消费者, 读者—写者,
- 并发问题:
- 线程安全:
- 不保护共享变量的函数: 全局变量, static变量
- 保持调用状态的函数, 例如rand函数不是线程安全的。当前调用结果依赖前次调用的中间结果, 使rand函数线程安全的方法是, 重写他,使其不在依赖static变量。
- 返回指向静态变量的函数
- 调用线程不安全函数的函数
- 主要韩式,使用,返回,依赖,共享变量的问题。
- 可重入函数:
- 特点在于倍多个线程调用时,不会引用任何共享数据,可重入是线程安全的 真子集。
- 可重入函数通常要比线程安全的函数要高效一点: 因为他们不需要同步操作,
- 竞争,死锁
- 线程安全:
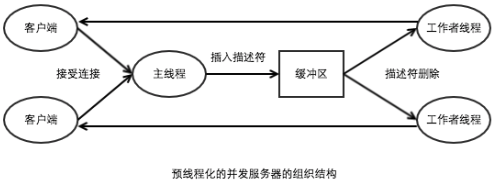
- 基于预线程化的并发服务器: 通过生产者消费者一个模型,
- 服务器是有一个主线程和一组工作者线程构成的
- 主线程不断的接受来自客户端的连接请求,并讲的到的连接请求描述符放到一个缓冲区中
- 每一个工作者线程 反复的从共享缓冲区中消费描述符。
- 使用线程提高并行性: 操作系统内核在多个核上并行的调度这些并发线程。并行程序常常被写为 每个核上只运行一个线程。
- 概念:
- 总结:
1. 进程由内核调度,因为拥有独立的虚拟地址空间, 所以需要显示的IPC机制,来实现共享数据,同时 编程模型简单一致 ( 能否利用多核?)
2. 事件驱动 使用I/O多路复用 显示的调度 并发逻辑流。以为在同一个进程中,所以共享数据变得简单, 复杂度比较高 (只能是单核应用了,但是能够高效利用IO,)
3. 线程是两个的结合, 能够充分利用多核优势。但是调用函数,必须具有一种成为线程安全的性质。(信息同步,信号量,线程安全函数, 使得编程起来比较困难)
4. 无论那种并发机制,同步对共享数据的访问都是一个困难的问题