
linux-interface-14
文件系统
文件系统是对文件和目录的组织集合
设备
- 划分
- 实际设备(键盘、鼠标、磁盘)和虚拟设备(不存在与之对应的硬件,内核为其提供的一种抽象。比如ssh登录?)
- 字符类型,块设备。字符类型有键盘、终端等。典型的块类型设备是磁盘
- 设备专用文件: 与系统的某个设备相对应,每个设备类型都有与之相对应的设备驱动程序。用来处理设备的所有IO请求。设备驱动程序属于内核代码,由设备驱动程序提供的API是固定的,主要包含(open, close, read, write, mmap, ioctl),由于这些统一一致的API,隐藏了每个设备在操作方面的差异。
- 如何确定驱动程序:
- 设备文件的I节点中记录了设备的主、辅ID。
- 主、辅ID: 主ID标识一般的设备等级,内核用来寻找设备驱动程序,辅号在主ID中的标识唯一的特定设备。ls -l 会展现出设备文件的主、辅ID。(不知道是不是需要对于设备类型文件才行)
- 设备驱动程序会向内核注册 自己与特定 主ID的关联关系。内核基于此建立 设备到设备驱动程序的关联关系。(内核是不会通过设备文件名来查找驱动程序的,猜想也是如此, 不可能根绝简单的字符串来匹配驱动程序)
磁盘
- 磁盘分区: 可以将磁盘分成一个或者多个分区,内核将每个分区视为/dev路径下的单独设备。可以使用fdisk 来决定磁盘分区的编号、大小和类型。fdisk -l 列出磁盘的所有分区, linux 文件/proc/partitions 记录了分区的主辅设备编号、大小和名称。
- 磁盘分区可以容纳任何类型的信息,但通常包含以下:
- 文件系统
- 数据区域,作为裸设备对其进行访问
- 交换区域: 供内核的内存管理用。可以通过mkswap命令创建交换区域,系统调用swapon, swapoff, 启用、关闭磁盘作为内存交换区。linux文件 /proc/swaps 用来查看当前激活的交换区信息。
文件系统
- linux支持的文件系统有:
- 传统的ext2
- 各种原生的UNIX文件系统,比如Minix, System V以及BSD文件系统
- 微软的FAT,FAT32已经NTFS文件系统
- ISO9660 CD-ROM文件系统
- Apple Macintosh 的 HFS
- 一系列日志文件系统: 还包括etx3, ext4, JFS,XFS等
- linux 2.6.14中添加了 FUSE(用户空间文件系统)工具,采用这一机制,可谓内核添加挂钩,以便以用户空间程序 来是实现完整的文件系统,而无需对内核进行修补和重新编译
以下为ext2文件系统 为例
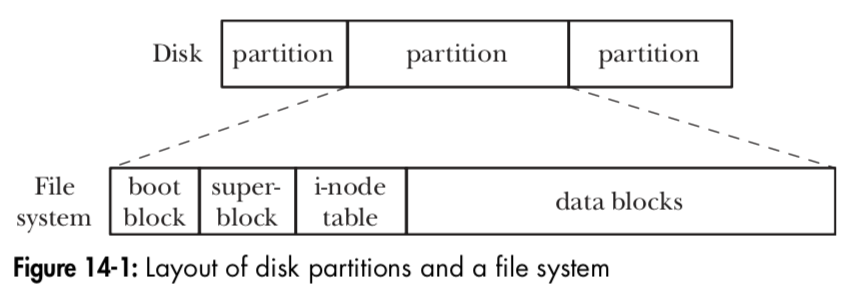
- 文件系统的组成部分:
- 引导块: 文件系统的首块,不能为文件系统所用,用来引导操作系统的信息。操作系统只需要一个引导块,但是所有的文件系统都设有引导块。
- 超级块: 紧随引导块之后的一个独立块。其包含文件系统有关的详细参数: 1)i节点表容量。 2)文件系统中的逻辑块大小, 3)以逻辑块计,文件系统的大小。驻留于同一块磁盘上的不同文件系统,其类型、大小以及参数设定都有所不同(比如逻辑块)这也是将一块磁盘划分多个分区的原因之一。
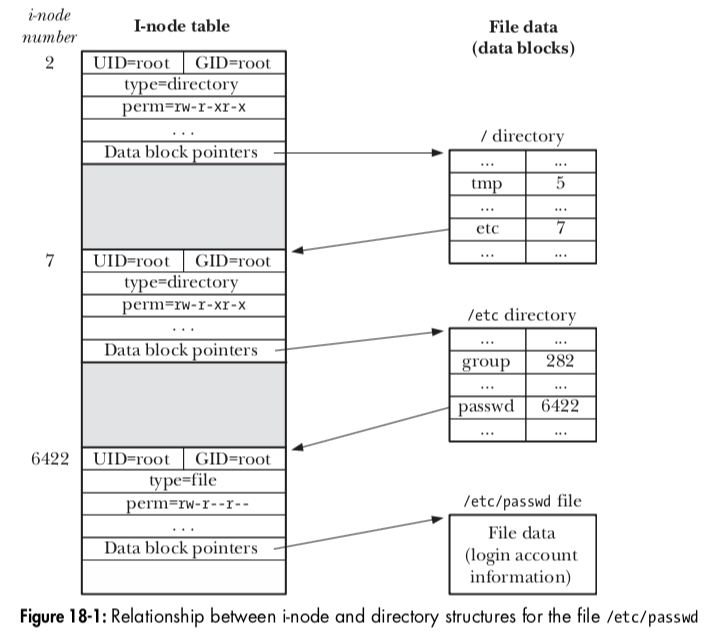
- i节点表:与文件系统中的每个文件、目录 一一对应。记录了文件的相关信息
- 数据块: 用于存放数据,占据文件系统空间中的大部分空间
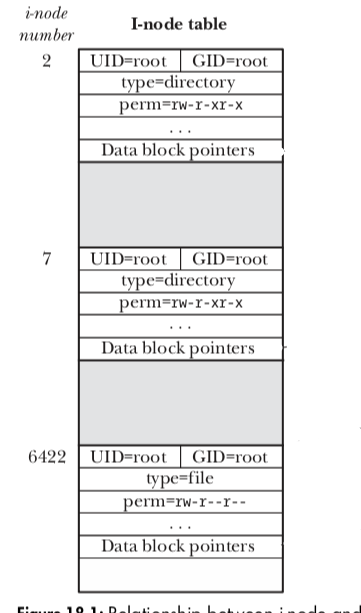
i节点
对于文件系统中的每个文件(所有东西,包括:目录、链接、etc) 都有一个i节点与之对应。对i节点的标识为顺序数字,ls -li命令第一列为i节点号
- 其维护的信息主要有
- 文件类型(常规文件、目录、符号链接、设备等)
- 文件属主(UID)
- 文件属主(GID)
- 3个权限
- 3个时间戳
- 指向文件的硬链接数(hard link)
- 文件的大小(字节为单位)
- 实际分配给时间的块数量 (不同于上面的文件大小,因为文件空洞的存在)
- 指向文件数据块的指针(i-node-entry)
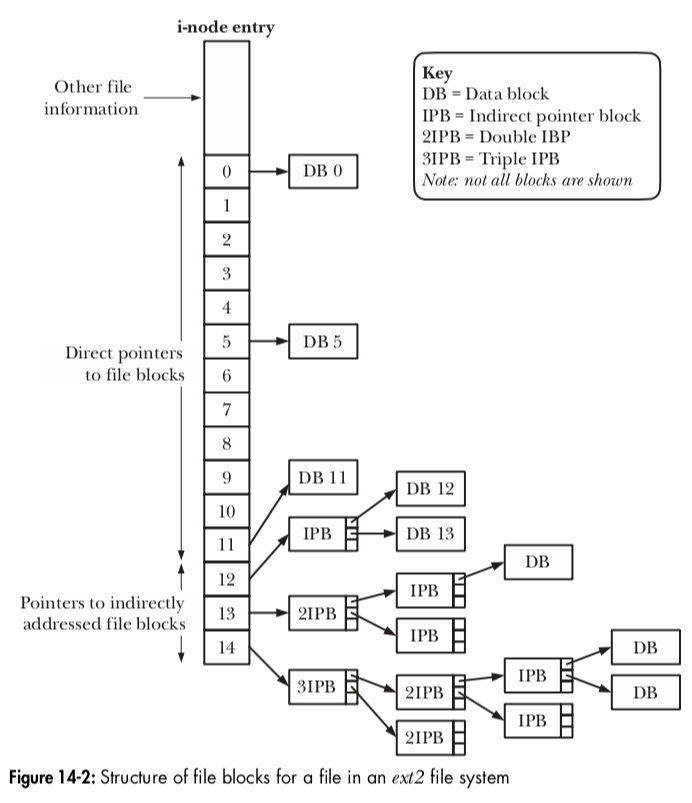
虚拟文件系统(VFS)
是一种内核特征,通过为文件系统操作创建抽象层来解决、屏蔽,各种不同文件系统的不同的实现细节
- VSF对文件系统定义了一套通用接口,所有与文件相关的程序都会使用这一接口
- 每种文件系统都会提供VFS接口的实现
- 接口的操作与涉及文件系统和目录的所有常规系统调用相对应,有: open, read, write, lseek, close, truncate, stat, mount, umount, mmap, mkdir, link, unlink, symlink, rename
- 并不是所有的文件系统都支持所有的VFS操作,对于这种情况, 底层文件系统调用将错误代码传回VFS层面,并传递到应用层面
挂载 mount
- mount 命令:
- mount device directory, 将device的文件系统挂在到directory所指定的目录下。可以使用umount卸载,并在其他地方重新挂载。(linux 2.4.19) 之后内核支持针对每个进程的挂载空间,每个进程都能够拥有自己的挂载空间。
- mount 不带参数, 可以列出当前已挂载的文件系统
- linux /proc/mounts 可以查看当前已经挂载的文件系统列表。因为是内核数据结构的接口,所以是比较精确的。在引入经程级别的挂载空间后, /proc/PID/mouns 为进程的挂载信息,而 /proc/mounts 链接到 /proc/self/mounts
- /etc/mtab 包含同样的信息,只是会更加详细些,其中会包含了传递mount命令的参数, mount,umount 命令会自动维护 该文件,然而 系统调用 mount, umount 并不会维护该文件,导致可能会不够准确
- /proc/mounts, /etc/mtab 文件的格式如下:
/dev/sda1 / ext2 rw 0 0 从左到右的意思是: 挂载设备名,挂载点,文件系统类型, 挂载标志, (后面的详细参看手册)
- 相关系统调用:
mount系统调用中的mountflags具有重要作用,其决定着对整个设备文件系统类型的处理。例如, MS_RDONLY, 以只读方式挂载,在此文件系统上只能读,而不能创建和修改。- 在多个挂载点挂载文件系统: 在挂载点一做出的改变,在挂载点二下立即可见。因为存在进程级别的挂载空间,所以操作并不影响之前的进程,只影响之后的进程挂载点。
- umount, umount2 系统调用卸载已挂载的文件系统。无法卸载正在使用中的文件系统, 这一文件系统中有文件被打开,或者进程的当前工作目录在此文件系统下,是无法被卸载的,返回EBUSY错误。
-
umount2(const char * target, int flags): 其中flags有如下几个选项, MNT_DETACH(lazy卸载, 不在允许新的进程访问挂载点, 等使用中进程不在使用挂载点时候,卸载文件系统), MNT_EXPIRE(首次调用并且处于空闲状态,将被标记 为到期,非空闲失败,二次调用,仍处于到期状态,则卸载文件系统。可用于卸载在某段时间内未用的文件系统), MNT_FORCE(强行卸载文件系统,可能会造成数据丢失)
- 绑定挂载: 可以在文件系统目录层级 挂载目录或者文件。将导致文件或者目录在两处都可见。不同于多个挂载点挂载、有些类似于硬链接,区别在于: 1) 绑定挂载可以跨越多个文件系统挂载点 2)可针对目录执行绑定挂载。绑定挂载需要指定特殊标志才能够递归的挂载 子挂载
shell mkdir d1 mkdir d2 mount --bind d1 d2
虚拟内存文件系统(tmpfs):
linux支持驻留于内存的虚拟文件系统。tmpfs最为复杂。不仅使用RAM还能够利用交换空间。/proc/mount 即是此类文件系统的实现,可以创建tmpfs文件系统并挂载至/tmp来改善编译器类似的频繁使用/tmp目录的应用程序的性能。
内核还将此类文件系统用于:
- 实现System V共享内存和共享匿名内存映射
- 挂载于/dev/shm的tmpfs文件系统,为glibc用以实现POSIX共享内存和信号量
文件属性
- int stat(const char * pathname, stuct stat * statbuf): 系统调用: 获取与文件有关的信息, 大部分都来自于i节点, struct stat结构如下:
stuct stat { dev_t st_dev; dev_t st_rdev; ino_t st_ino; mode_t std_mode; n_link_t st_nlink; uid_t st_uid; g_id_t st_gid; time_t st_atime; time_t st_mtime; time_t st_ctime; }部分详细解释:
- st_devo 字段标识文件所驻留的设备。st_ino 为文件的i节点,两者标识文件系统中的唯一文件。设备文件的i节点,st_rdev 字段包含了主、辅ID, 否则st_dev 包含信息
- st_uid, st_gid 标识文件属主。 st_nlink 包含了指向文件的硬链接数目。 st_mode 标识了文件类型、已经权限。
- st_atime, st_mtime, st_ctime, 为文件时间戳, 分别标识: 文件上次访问时间、修改时间、以及文件状态修改时间。
- 系统调用: utime, utimes, utimensat 都可以修改文件的时间戳。
- 新建文件的属性: 新建文件时的属主取决于进程的有效用户ID。新建文件的组ID是多变的,下面为ext2下面新建文件组ID所遵循的规则:
| 文件系统mount选项 | 父目录设定set-group-id 标记 | 新建文件的组ID取值 |
|---|---|---|
| -o grpid, -o bsdgroups | 忽略 | 父目录组ID |
| -o nogrpid, -0 sysvgroups | 无 | 进程的组id |
| -o nogrpid, -0 sysvgroups | 有 | 父目录组id |
-
chown 系统调用, 可以更改文件属主, 权限为: 1)特权级别进程(root) 2)进程的有效用户ID与文件的用户ID匹配。当文件的属主或者属组发生了改变时,set-user-id, set-group-id 权限位会关闭。改变的是目录的时候, 其set-group-id并不会发生改变。目录的set-group-id 并不是为了创建 set-group-id程序,而是为了控制在该目录下创建文件的所有权。
-
目录下的权限
- 权限:
- 读权限: 可以ls 目录下的内容。
- 写权限: 可在目录下创建、删除文件(删除文件对文件本身并不需要权限)
- 可执行权限: 可访问目录中的文件,也成为search权限
- 访问文件时候, 需要拥有对路径名所有的目录的执行权限, /home/mtk/x, 需要对 /、/home、/home/mtk 拥有可执行权限。但是若在/home/mtk/sub1下,通过相对路径 ../sub2/x 访问。那么只需要 /home/mtk 、/home/mtk/sub2 这两个目录的可执行权限,而不需要 /、/home 的权限。(奇怪,应该保持一致性比较好)
-
对目录权限的解释:
因为目录的特殊结构(目录的内容其下的文件、目录等的i节点列表),可以这样理解设定三种权限的理由: 读权限, 可以访问目录的数据结构。可执行权限,则可以查看目录内容的i节点详细信息。写权限,意味着可以修改目录内容,所以可以删除目录下的文件(即是修改目录内容的i节点列表) - 若是拥有对目录的可执行权限, 而没有读权限。只需要知道目录内的文件名称,则仍可以进行访问,但不能列出目录下的内容。在控制对公共目录内容的访问时,非常有用。
- 文件系统的权限检查(包含目录、文件):只在初次调用时候,进行检查,open文件之后的fd,再次对其进行操作,是不再会进行检查的。规则如下:
- 特权进程, 授予访问权限
- 若进程的有效用户ID与文件的用户ID相同,内核会根据文件的属主权限,授予进程相同的权限。
- 若进程的有效组ID或任意附属组ID与文件的组ID相匹配。根据文件的属组权限,授予进程
- 若上面都不满足, 内核根绝other授予进程权限。
内核检查会在最后时候,即是未能通过调用规则的检查的时候,才会检查检查是否属于特权进程。
上述检查可能造就一些奇怪的现象(从代码逻辑上来看是正常的): 比如文件的owner没有rw权限,
同样适用于目录的权限检查, 但是特权进程总是拥有可执行权限(即是总是可以搜索),特权进程总是拥有通过任何的权限检查
-
Sticky位: 现在的UNIX的Sticky权限位 其限制删除的作用,为目录设定权限位时候, 表明非特权进程时,只有对目录有写权限+为文件或目录的属主时才能对目录下的文件进行 删除、重命名操作。(可以用于建立多个用户共享的目录文件, 每个用户管理自己的文件、访问其他人的文件。但是不能删除其他人的文件) 典型的应用在/tmp 目录下, chmod +t 可以添加 sticky位,
-
进程的文件创建掩码: umask 是一种进程属性, 当进程创建文件或者目录时候,该属性执行屏蔽那些权限位。进程的umask通常继承父shell, 所以可以在shell中使用umask来改变shell进程的umask,进而影响所有的shell子进程。umask(mode_t mask) 系统调用总是调用成功,并返回之前的umask数值。
- i节点扩展属性(EA)
目录和链接的实现结构
- 目录的实现结构:
- i节点的类型标记为目录
- 目录内容是经过特殊组织的文件表格(硬链接列表): 文件名和i-node编号。
- 不能够read目录内容, 直接编辑目录内容是不允许的,不具有可移植性。需要使用相关的系统调用, open, link, mkdir, symlink ,unlink, rmdir etc
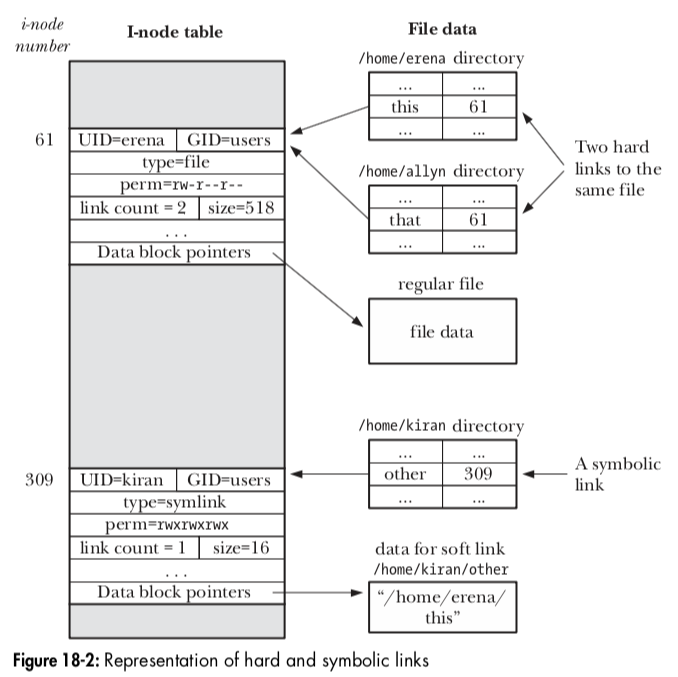
- 硬链接: 创建链接指向相同的i-node节点,成为硬链接。会改变 指向文件的i-node节点的 链接数。限制有: 1) 因为采用i-node编号,导致不能跨越文件系统。 2)不能为目录创建硬链接,会导致诸多的系统程序陷入混乱的链接环路中。
- 符号链接: 特殊的文件类型, 内容为另一个文件的名称(字符串)
- ln -s 创建, 内容可以是绝对路径和相对路径,解释相对路径时,以链接本身的位置作为参照点。
- 符号链接的地位不如硬链接,i节点并不体现符号链接数量。即便移除了文件,链接依然存在,成为空连接。甚至可以创建不存在文件的链接。
- 因为符号链接的内容为字符串,所以可以跨越文件系统。一些系统调用中对符号链接进行解析,因为可能存在环路问题,所以规定了街引用的一个次数范围。_POSIX_SYMLOOP_MAX 常量规定了最大次数限制。(无论系统调用是否对符号链接进行解析,其总是对符号链接中的目录部分进行接引用,区分在于是否对文件接引用),
- 权限为引用的文件的权限。
系统调用:
- link(const char * oldpath, const char * newpath); 创建硬链接, oldpath 不应为符号链接,否则不具有可移植性。
- unlink(const char * pathname): 如果此链接为最后一个指向文件的,此操作还会删除文件本身。
- 都不能操作目录, 与符号链接
-
文件内容的删除: 内核除了维持i-node节点的链接数目之外,还对文件的打开文件描述符计数。只有全部的计数为0时候,文件才会真正的消失。这意味着, 存在多个硬链接, 只有删除全部删除硬链接的时候,才会删除文件本身,且不存在打开的文件描述符。否则文件本身依然存在,并且可以被读取。
- rename(const char * oldpath, const char * newpath): 可以重命名文件、目录。 调用仅仅操作目录条目, 而不移动数据,更名既不影响指向该文件的硬链接,也不影响打开文件描述符的任何进程。(这些文件描述符在open调用返回之后,与文件名再无瓜葛)
规则:- newpath 存在则将其覆盖
- newpath与oldpath 指向同一文件, 则不操作
- 系统调用不对参数进行解引用,意味着可以操作符号链接
- oldpath 是文件的时候,不能更名为目录
- oldpath是目录的情况下, newpath目录不能存在或者是空目录。且newpath不能包含oldpath的前缀, 如 /home/mtk, -> /home/mtk/bin
- oldpath、newpath 需要为同一文件系统,因为目录的内容为硬链接列表组成。硬链接的i-node节点指向必须是同一文件系统。(区别于 mv系统命令, mv能够跨越文件系统, 其操作 复制内容, 其在同文件系统上的表现还需要验证)
- symlink(const char * filepath, const char * linkpath): 创建filepath(路径名)文件、目录的一个新的符号链接。filepath 可是相对路径或者绝对路径,相对路径会经常显现一些超乎意外的情况,所以建议是绝对路径。filepath 可以存在或者不存在,因为即便存在依然可能会被删除,造成linkpath的空连接。
- readlink(const chart *pathname, char * buffer, size_t bufsiz): 获取符号链接本身的内容,系统调用将符号链接的内容放到buffer中。
- mkdir(const char * pathname, mode_t mode): pathname可以使相对路径或绝对路径,目录的set-user-id 总是关闭(因为没有作用), mode 中的 set-group-id 设定会被忽略。系统调用所创建的只是路径名中最后的部分,如果中间部分不存在则调用失败。 SUSv3 并未要求目录中包含.、.., 只是要求存在时候能够正确解释,所以,可移植性的程序不能假定总是存在这些条目。
- rmdir(const char * pathname):要求被删除目录内容为空,才能调用成功。
- remove(const char *pathname):c标准库中的函数, 并不是系统调用。 不会解引用。移除一个文件或一个空目录。pathname 为文件,remove 会调用unlink, 是目录时,remove 调用rmdir.
进程都有两个目录相关属性: 1)根目录, 2)工作目录。没想到过还可以修改根目录
- 进程的当前工作目录:定义了该进程解析相对路径的起点, 继承自父进程。
- getcwd(char * wdbuf, size_t size): 拥有获取当前进程的工作目录, 当前工作目录的最大字符串长度应小于4096 的字节限制。超出将不再可靠。
- chdir(const char *pathname): 更改调用进程的当前工作目录,可以为符号链接。
- /proc/PID/cwd 为进程当前工作目录的映射
- 进程的根目录: 该目录是解释绝对路径的起点,继承自父进程。
- chroot(const char *pathname): 系统调用改变进程的根目录,目的为监理一个chroot监禁区。将所有对绝对路径的解释设定为一个目录的起点。将应用程序设定为文件系统的特定区域。
- 需要将 根目录的 .与.. 设定为自身, 防止根据相对路径,逃出监禁区
- 并不是所有的程序都可以运行在监禁区,因为大多数程序与共享库之间采用动态链接的方式。因为需要复制一套标准的共享库来实现运行动态链接的程序(通过绑定挂载可以实现共享库共享)
- 不能在监禁区中方式set-user-id-root 程序,方式获取root的权限
- 需要chdir, 防止通过相对路径逃出监禁区
- 如果进程之前持有监禁区之外的文件描述符,可以逃出监禁区
- 可以通过套接字传递监禁区之外的文件描述符,所以需要避免
- 总结: chroot调用并不能真正的成为安全的控制机制,因为逃出监禁区的方式有很多,还不如实现更加现代的docker容器技术来避免。
realpath(const char * pathname, char * resolved_path): 对路径解析为绝对路径。
dirname, basename: 将路径名解析成, 目录和文件名两部分。